


千锋教育Python大数据分析+大模型应用开发课程
【开课时间】2025/11/18【上课地点】北京【学习费用】详询
什么是数据分析
数据和智能是第四次和第五次工业革命的基石,也是现代企业最为重要的生产资料。目前,各行各业对信息技术的依赖程度都在不断加深,无论是政府行为还是商业行为,都严重依赖于数字化建设。在大数据时代,我们经常会感到数据越来越多,但是要从数据中发现有价值的信息却越来越难。数据分析就是从原始数据中获取商业价值的过程,通过对原始数据的收集、加工和整理,使用统计方法、可视化技术、挖掘算法实现数据的透视、呈现和解读,最终获得有价值的信息和业务洞察,并以此为基础指导企业的决策。

数字化人才国内现状
1、缺人才 数字化人才缺口严重
面对快速到来的数字化时代,存量的数字化人才并不多外招难度大,且“需求>供给",进一步加剧了数字化人才供给难题。
2、缺标尺 数字化人才选育缺少统一标准
数宇化人才属于"新生人才物种”,具有复合性特点自带"多技能包”,大多数企业还不确定公司员工目前的能力和所需技能之间的差距,也就无法准确测量技能鸿沟,进行选拨和整体能力规划。
3、缺方法 数字化转型升级缺少张提规划
企业在持续打造学习型组织的过程中,如何搭建一支强有力的数字化人才方阵,持续性、系统性获取知识.用学习驱动融合,赋能数字化组织,推动人和组织的持续进化,成为重要课题。
4、缺抓手 如何找准切入点实践数字化转型
一方面,随着数字化变革进入深水区,实操业务场景陆续落地,企业开始面临能力供给与需求不匹配、场景专业性无法快速提升、对新兴克合格局不适应等-系列严峻挑战。另一方面,如何找到抓手,“在业务场景中学习"在实战项目中学习”迅速掌提数宇化技能跟上企业数字化转型节奏,成为重要突破口。
近年来,随着信息化技术的普及以及大数据和人工智能技术在各行各业的应用,市场对数字化人才的需求逐年递增,其中数据治理工程师、业务数据分析师和数据挖掘工程师的人才缺口最大。中国信息通信研究院发布的《数字经济就业影响研究报告》指出,2020 年我国数字化人才缺口接近 1100 万,而且伴随传统行业的数字化转型以及全行业的数字化推进,人才需求缺口仍然在持续放大。无独有偶,波士顿咨询公司(BCG)发布的《数字经济下就业与人才研究报告》也指出2035 年中国整体数字经济规模将接近,总就业容量将达到4.15亿,如果不实施有效的人才战略,到时可能出现一个巨大的人才缺口,不只是在数量上,还有技能方面的缺口。另一方面,由于互联网行业已经不再处于流量红利时代,市场竞争日趋复杂和激烈,如何实现低成本获客、如何培养忠诚用户以及如何保持营收增长是每个企业都必须直面的问题。在这样的背景下,无论B端还是C端业务,都需要实现数字化、精细化运营,企业对数据驱动决策的依赖达到了前所未有的高度,数据分析师就是完成上述工作内容最为重要的角色。
数据分析的学习内容
数据分析就是“数据思维+分析工具",其中,数据思维解决了如何认知和解读数据的问题,而分斤工具则帮助我们实现了快速便捷的数据处理和结果早现。
课程迭代升级数据科学为王
课程概述
本课程面向大数据时代各行各业对数据学科的需求,通过从零开始的系统化训练,帮助学员养成数据分析思维,掌握数据分析工具,理解数据治理方法,最终培养出商业数据分析师、数据挖掘工程师和数据治理工程师等现代企业急需的人才。本次课程升级在原有内容基础上进一步强化了商业画布梳理、指标体系建设、数据仓库建设、A/B 测试、用户画像、因果推断等知识,除此之外,还增加了 A 大模型辅助数据分析和基于大模型的 A 智能体开发等内容,让学员在真实的项目中感受数据分析的魅力,认识数据科学的价值,最终掌握用数据驱动企业决策的综合能力。
大纲升级
在深入调研企业数字化运营需求的基础上,由多名资深数据分析师和企业数据架构师历时八个月匠心打磨。课程聚焦业务知识,培养数据思维,深耕分析方法,强化分析工具,紧扣时代脉搏每一次的变革都是为了让我们的学员在未来更具核心竞争力。
大纲更新依据
数千名学员反馈
统计数千名千锋老学员所在公司实际使用的技术和工具以及学员在求值面试中反馈的问题
企业顾问实战
结合多名资深数据分析师的工作经验,汇聚阿里、百度、美团小红书等一线名企大咖的建议。
教研学院深入探索
专业教研团队按企业实际需求和学员学习规律设计课程,定期选代更新。
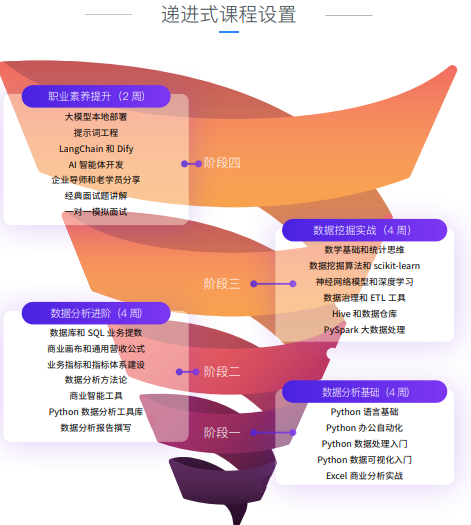
递进式课程设置
阶段四
职业素养提升(2 周)
大模型本地部署
提示词工程
LangChain 和 Dify
AI智能体开发
企业导师和老学员分享
经典面试题讲解
一对一模拟面试
阶段三
数据挖掘实战(4 周)
数学基础和统计思维
数据挖掘算法和 scikit-learn
神经网络模型和深度学习
数据治理和 ETL 工具
Hive 和数据仓库
PySpark 大数据处理
阶段二
数据分析进阶(4 周)
数据库和 SQL 业务提数
商业面布和通用营收公式
业务指标和指标体系建设
数据分析方法论
商业智能工具
Python 数据分析工具库
数据分析报告撰写
阶段一
数据分析基础(4 周)
Python 语言基础
Python 办公自动化
Python 数据处理入门
Python 数据可视化入门
Excel 商业分析实战
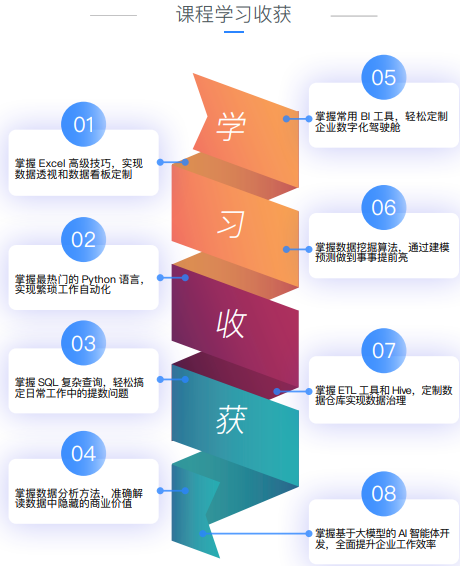
学习收获
01掌握 Excel 高级技巧,实现数据透视和数据看板定制
02掌握最热门的 Python 语言,实现繁琐工作自动化
03掌握 SQL 复杂查询,轻松搞定日常工作中的提数问题
04掌握数据分析方法,准确解读数据中隐藏的商业价值
05掌握常用 BI 工具,:轻松定制企业数字化驾驶舱
06掌握数据挖掘算法,通过建模预测做到事事提前亮
07掌握 ETL 工具和 Hive,定制数据仓库实现数据治理
08掌握基于大模型的 A 智能体开发,全面提升企业工作效率

课程升级内容
增加了 Excel 数据分析新功能和 AI插件辅助数据分析
强化了 Python 语言在日常工作自动化方面的应用
强化了商业画布制作和商业模式的梳理
增加了因果推断应用场景和相关案例
增加了商业智能工具接入 DeepSeek辅助分析案例
强化了 A/B 测试的案例和细节拆解
增加了统计学赋能增长黑客的内容
增加了神经网络模型和深度学习相关内容
强化了风控算法和风控模型相关知识及其应用场景
强化了 PySpark 在大数据分析中的应用
增加了本地大模型部考及相关工具应用的内容
增加了基于大模型的智能体(AlAgent)开发相关内容
增加了 LangChain 和 Llamalndex 框架相关内容
增加了大模型调优和 RAG 相关内容
增加了 Dify 框架应用相关内容
更新了数据分析师面试题库
课程优势
从基础入门学起,内容循序渐进
基础课都由教学经验丰富、责任心强且有亲和力的老师授课,对小白和新手非常友好,基础课阶段除了基础知识的学习,还穿插了行业认知课程,讲师带学生认识互联网行业和互联网产品,解读各种类型的行业分析报告
务实专业知识,铸造傍身技能
讲师会带领学员认识、了解各类互联网产品的指标体系以及对应的分析方法,指导学生撰写数据分析报告,这是胜任数据分析师岗位的必要条件:所有内容都可以落地,不是空洞和枯燥的理论讲解
企业级项目实战,真实经验在手
课程中实战项目完全匹配企业需求,能够帮助学员掌握多项硬核技能,通过指导学员参与还原企业开发场景的干锋多学科联合项目,学员可以进一步体会到所学知识在真实产品运营中的应用
1对1就业指导,助力顺利就业
专职职业发展老师,根据不同学员学习、就业情况进行1对1指导,从表达训练、简历撰写、职场礼仪、面经分享、面试技巧到模拟面试全流程针对化指导,助力学员顺利拿到满惠的 Offer

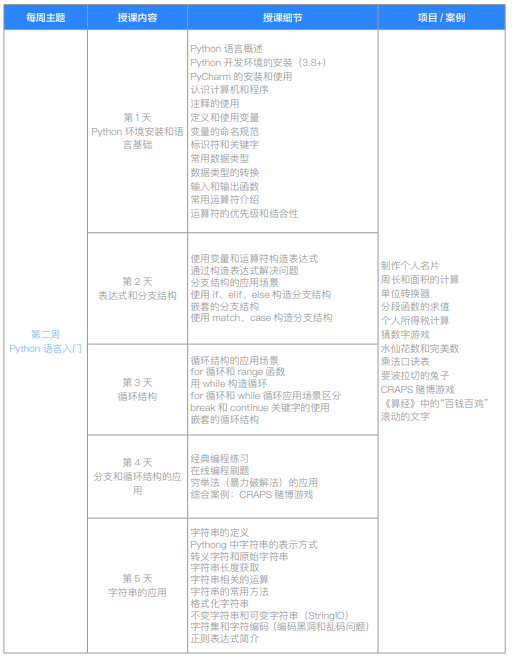

| 授课主题 | 授课内容 | 授课细节 | 项目/案例 |
| 第一周 Excel商业数据分析入门 | 第1天 数据分析概述 | 数据分析发展史 | 人力资源数据快速查询系统 |
| 数据分析对现代企业的重要性 | 销售数据可视化看板 | ||
| 数据分析在各行业的应用 | 招聘门户网站数据看板 | ||
| 数据分析师的日常工作 | 企业营收数据报表制作 | ||
| 数据分析师的职业规划 | 游戏运营数据报表制作 | ||
| 数据分析师招聘需求解读 | Excel面试真题详解 | ||
| 安装和认识Excel | |||
| 第2天 Excel 快速上手 | 数据的输入、填充和格式化 | ||
| 定位条件和查找替换 | |||
| 数据筛选和高级筛选 | |||
| 条件格式和排序工具 | |||
| 数据的合并和拆分 | |||
| 区域和表格的相互转换 | |||
| 表功能的使用 | |||
| 选择性粘贴 | |||
| 文档安全性相关设置 | |||
| Excel常用快捷键讲解 | |||
| 第3天 函数和公式计算 | 单元格的引用 | ||
| 锁定行和列 | |||
| 实现跨表引用 | |||
| 数学函数的使用 | |||
| 统计函数的使用 | |||
| 文本函数的使用 | |||
| 日期函数的使用 | |||
| 逻辑函数的使用 | |||
| 查找与引用函数的使用 | |||
| 第4天 透视表和商业数据看板 | 透视表的本质和应用场景 | ||
| 插入和定制透视表 | |||
| 常用统计图表及其应用场景介绍 | |||
| 基本图表的应用 | |||
| 高阶图表的应用 | |||
| 迷你图的应用 | |||
| 添加和定制切片器 | |||
| 第5天 Excel项目实战 | 实战1:商业数据分析看板项目 | ||
| 实战2:数据分析日报制作 | |||
| 第二周 | 第1天 | Python环境安装和语言基础 | |
| Python语言入门 | Python语言概述 | ||
| Python开发环境的安装(3.8+) | |||
| PyCharm的安装和使用 | |||
| 认识计算机和程序 | |||
| 注释的使用 | |||
| 定义和使用变量 | |||
| 变量的命名规范 | |||
| 标识符和关键字 | |||
| 常用数据类型 | |||
| 数据类型的转换 | |||
| 输入和输出函数 | |||
| 常用运算符介绍 | |||
| 运算符的优先级和结合性 | |||
| 第2天 | 表达式和分支结构 | 制作个人名片 | |
| 周长和面积的计算 | |||
| 单位转换器 | |||
| 分段函数的求值 | |||
| 个人所得税计算 | |||
| 数字游戏 | |||
| 使用变量和运算符构造表达式 | |||
| 通过列表表达式解决问题 | |||
| 分支结构的应用场景 | |||
| 使用if、elif、else构造分支结构 | |||
| 嵌套的分支结构 | |||
| 使用match、case构造分支结构 | |||
| 第3天 | 循环结构 | 水仙花数和完美数 | |
| 乘法口诀表 | |||
| 斐波拉契的兔子 | |||
| CRAPS赌博游戏 | |||
| 《算经》中的“百钱百鸡” | |||
| 滚动的文字 | |||
| 循环结构的应用场景 | |||
| for循环和range函数 | |||
| 用while构造循环 | |||
| for循环和continue应用场景区分 | |||
| break和continue关键字的使用 | |||
| 嵌套的循环结构 | |||
| 第4天 | 分支和循环结构的应用 | 经典编程练习 | |
| 在线编程刷题 | |||
| 穷举法(暴力破解法)的应用 | |||
| 综合案例:CRAPS赌博游戏 | |||
| 经典编程练习 | |||
| 在线编程刷题 | |||
| 穷举法(暴力破解法)的应用 | |||
| 综合案例:CRAPS赌博游戏 | |||
| 第5天 | 字符串的应用 | 字符串的定义 | |
| Pythong中字符串的表示方式 | |||
| 转义字符和原始字符串 | |||
| 字符串长度获取 | |||
| 字符串相关的运算 | |||
| 字符串的常用方法 | |||
| 格式化字符串 | |||
| 不可变字符串和可变字符串(StringIO) | |||
| 字符集和字符编码(编码黑洞和乱码问题) | |||
| 正则表达式简介 | |||
| 字符串的定义 | |||
| Pythong中字符串的表示方式 | |||
| 转义字符和原始字符串 | |||
| 字符串长度获取 | |||
| 字符串相关的运算 | |||
| 字符串的常用方法 | |||
| 格式化字符串 | |||
| 不可变字符串和可变字符串(StringIO) | |||
| 字符集和字符编码(编码黑洞和乱码问题) | |||
| 正则表达式简介 | |||
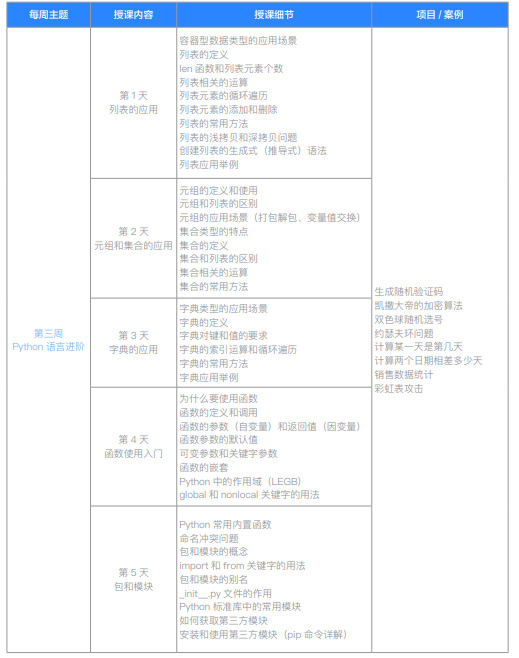
| 第三周Python 语言进阶 | 第1天 列表的应用 | ||
| 容器型数据类型的应用场景 | |||
| 列表的定义 | |||
| len 函数和列表元素个数 | |||
| 列表相关的运算 | |||
| 列表元素的循环遍历 | |||
| 列表元素的添加和删除 | |||
| 第2天 元组和集合的应用 | 列表的常用方法 | ||
| 列表的浅拷贝和深拷贝问题 | |||
| 创建列表的生成式(推导式)语法 | |||
| 列表应用举例 | |||
| 元组的定义和使用 | |||
| 元组和列表的区别 | |||
| 元组的应用场景(打包解包、变量值交换) | |||
| 第3天 字典的应用 | 集合的定义 | ||
| 集合和列表的区别 | |||
| 集合相关的运算 | |||
| 集合的常用方法 | |||
| 字典典型应用场景 | |||
| 字典的定义 | |||
| 第4天 函数使用入门 | 字典对键和值的要求 | ||
| 字典的增删改查和循环遍历 | |||
| 字典的常用方法 | |||
| 字典应用举例 | |||
| 为什么要使用函数 | |||
| 函数的定义和调用 | |||
| 函数的参数(自变量)和返回值(因变量) | |||
| 函数参数的默认值 | |||
| 第5天 包和模块 | 可变参数和关键字参数 | ||
| 函数的嵌套 | |||
| Python 中的作用域(LEGB) | |||
| global 和 nonlocal 关键字的用法 | |||
| Python 常用内置函数 | |||
| 命名冲突问题 | |||
| 包和模块的概念 | |||
| import 和 from 关键字的用法 | |||
| 包和模块的别名 | |||
| _init__.py 文件的作用 | |||
| Python 标准库中的常用模块 | |||
| 如何获取第三方模块 | |||
| 安装和使用第三方模块(pip 命令详解) | |||
| 第四周Python 语言应用 | 第1天 函数高级用法+C149C149:C153 | 一等函数的概念和使用 高阶函数的概念和使用 Python 内置函数中的高阶函数 Lambda 函数的应用 装饰器的概念 创建和装饰器函数 函数的递归调用 递归函数的优化 | |
| 第2天 面向对象编程概述 | 面向对象编程思想 面向对象的应用场景 面向对象的核心概念(类和对象) 定义类(数据抽象和行为抽象) 创建对象(构造器函数) 给对象发消息(调用对象方法) 类方法和静态方法 dir 函数的使用 汉诺塔问题 骑士周游问题 八皇后问题 记录函数的执行时间 数字时钟和计时器 Black Jack 扑克游戏 奥特曼打小怪兽 工资结算系统 | ||
| 第3天 面向对象编程进阶 | 常用的魔法方法 运算符重载 继承的概念 方法定义和多态 多重继承和 MRO 问题 | ||
| 第4天 Python 办公自动化 | Python 文件读写 异常处理机制 Python 读写 Excel 文件 Excel 公式计算和图表生成 Python 生成 Word 文档 Python 处理 PDF 文件 | ||
| 第5天 用 Python 处理数据 | 数据的保存方式 JSON 格式 从 API 接口中获取数据 数据的描述性统计信息 statistics 模块的应用 数据可视化 pyecharts 库的使用 | ||
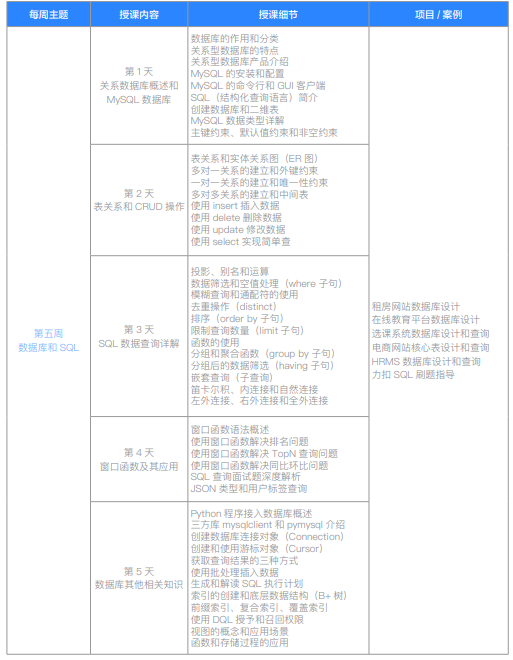
| 第五周数据库和SQL | 第1天 关系数据库概+C154:C159述和MySQL数据库 | 数据库的作用和分类 关系型数据库的特点 关系型数据库产品介绍 MySQL的安装和配置 MySQL的命令行和GUI客户端 SQL(结构化查询语言)简介 创建数据库和二维表 MySQL数据类型详解 主键约束、默认值约束和非空约束 | |
| 第2天 表关系和CRUD操作 | 表关系和实体关系图(ER图) 多对一关系的建立和外键约束 一对一关系的建立和唯一性约束 多对多关系的建立和中间表 使用insert插入数据 使用delete删除数据 使用update修改数据 使用select实现简单查 | ||
| 第3天 SQL数据查询详解 | 投影、别名和运算符 数据筛选和空值处理(where子句) 模糊查询和通配符的使用 去重操作(distinct) 排序(order by 子句) 限制查询结果(limit子句) 分组和聚合函数(group by子句) 分组后的数据筛选(having子句) 嵌套查询(子查询) 笛卡尔积、内连接和自然连接 左外连接、右外连接和全外连接 租房网站数据库设计 在线教育平台数据库设计和查询 电商网站核心数据库设计和查询 HRMS数据库设计和查询 力扣SQL刷题辅导 | ||
| 第4天 窗口函数及其应用 | 窗口函数语法概述 使用窗口函数解决排名问题 使用窗口函数解决TopN查询问题 使用窗口函数解决同比环比问题 SQL查询面试深度解析 JSON类型和用户标签查询 Python程序接入数据库概述 三方库mysqlclient和pymysql介绍 创建数据库连接对象(Connection) 创建和使用游标对象(Cursor) 获取数据库查询结果的三种方式 | ||
| 第5天 数据库其他相关知识 | 生成批处理插入数据 使用explain分析执行计划 索引的创建和底层的数据结构(B+树) 前缀索引、复合索引、覆盖索引 使用DQL授予和收回权限 视图的概念和应用场景 函数和存储过程的应用 | ||
| 第六周 数据分析思维和商业智能工具 | 第1天 指标和指标体系 | 互联网行业认知 互联网产品的定义和商业模式认知 互联网营收通用公式拆解 互联网产品和用户的生命周期 指标的概念和常用业务指标 北极星指标和伴随指标 指标体系的搭建和作用 如何为企业搭建指标体系 数据规划的OSM模型和UJM模型 | |
| 第2天 数据分析方法论和模型 | 使用对比法发现问题 通过拆解法缩小问题范围 通过漏斗法定位问题环节 通过相关分析找寻业务抓手 通过象限分析法进行分群 RFM模型用户价值分析 AIPL模型和运营三件套 AARRR模型和RARDA模型 | ||
| 第3天 Power BI入门 | Excel中的Power Query插件介绍 从Excel升级到Power BI的理由 Excel Desktop的安装 Power BI的组网网站 Power BI的功能帮助功能 Power BI功能初体验 输入和连接数据 常用App商业画布制作 电商客服指标分析和可视化 连锁咖啡店产品和用户数据分析 零售行业利润下滑诊断分析 云产品销售业绩下滑诊断分析 人力资源数字化大屏 | ||
| 第4天 Power BI数据清洗和建模 | Power Query编辑器的使用 更改数据类型 处理重复值和异常值 数据的排序和筛选 删除行和列 列的合并和拆分 添加自定义列 合并和追加表数据 表关系的编辑和删除 | ||
| 第5天 Power BI数据可视化和报表制作 | DAX的概念和语法 常用DAX函数 度量值和计算列 常用视觉对象的介绍 调整视觉对象的外观 从市场加载更多视觉对象 Power BI编交互和工具提示 数据的钻取 切片器的应用 动态数据单位和指标切换 Power BI报表设计 | ||
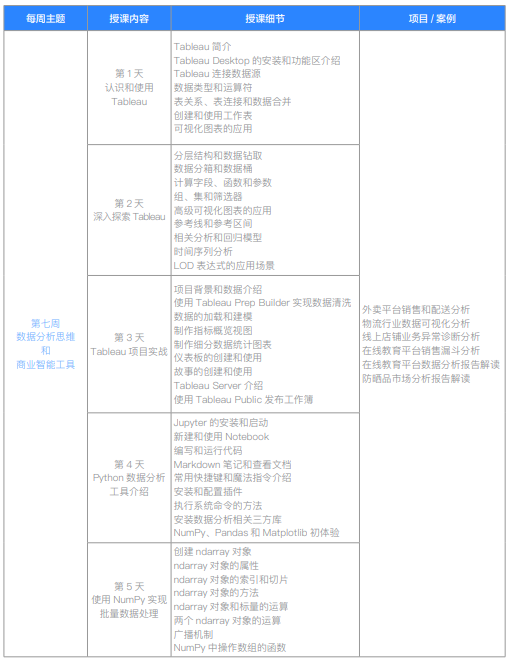
| 第七周 数据分析思维和商业智能工具 | 第1天 认识和使用Tableau | Tableau简介;Tableau Desktop的安装和功能区介绍;Tableau连接数据源;数据类型和运算符;表关系、表连接和数据合并;创建和使用工作表;可视化图表的应用 | |
| 第2天 深入探索Tableau | 分层结构和数据钻取;数据字段和数据桶;计算字段、函数和参数;组、集和筛选器;高级可视化图表的应用;参考线和参考区间;相关分析和回归模型;时间序列分析;LOD表达式的应用场景 | ||
| 第3天 Tableau项目实战 | 项目背景和数据介绍;使用Tableau Prep Builder实现数据清洗;数据的加载和建模;制作部分数据统计图表;仪表板的创建;故事的创建和使用;Tableau Server介绍;使用Tableau Public发布工作簿 | ||
| 外卖平台销售和配送分析;物流行业数据可视化分析;线上店铺业务异常诊断分析;在线教育平台销售漏斗分析;在线教育平台数据报告解读;防晒品市场分析报告解读 | |||
| 第4天 Python数据分析工具介绍 | Jupyter 的安装和启动;新建和使用Notebook;编写和运行代码;Markdown 笔记和查看文档;常用快捷键和魔法指令介绍;安装和配置插件;执行系统命令的方法;安装数据分析相关三方库;NumPy、Pandas 和 Matplotlib 初体验 | ||
| 第5天 使用NumPy实现批量数据处理 | 创建ndarray对象;ndarray对象的属性;ndarray 对象的索引和切片;ndarray对象的方法;ndarray对象和标量的运算;两个ndarray对象的运算;广播机制;NumPy中操作数组的函数 | ||
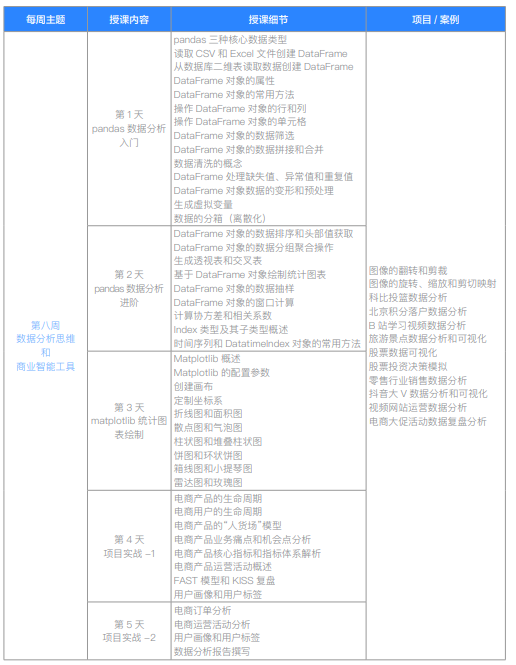
| 析思维和商业智能工具 | 第1天 pandas数据分析入门 | pandas三种核心数据类型 | |
| 读取CSV和Excel文件创建DataFrame | |||
| 从数据库二维表获取数据创建DataFrame | |||
| DataFrame对象的属性 | |||
| DataFrame对象的常用方法 | |||
| 操作DataFrame对象的行和列 | |||
| DataFrame对象的单元格 | |||
| DataFrame对象的数据筛选 | |||
| DataFrame对象的数据拼接和合并 | |||
| 数据清洗的概念 | |||
| DataFrame处理缺失值、异常值和重复值 | |||
| DataFrame对象数据的变形和预处理 | |||
| 生成虚拟变量 | |||
| 数据的分箱(离散化) | |||
| 第八周 数据分析思维和商业智能工具 | 第2天 pandas数据分析进阶 | DataFrame对象的数据排序和头部数据获取 | 图像的旋转和剪裁 |
| 基于Series和DataFrame对象的数据分组聚合操作 | 图像的旋转、缩放和剪切映射 | ||
| 生成透视表和交叉表 | 科比投篮客观数据分析 | ||
| DataFrame对象绘制折线图图表 | B站学习视频数据分析 | ||
| DataFrame对象的数据抽样 | 旅游景点数据分析和可视化 | ||
| DataFrame对象的面积计算 | 股票投资决策模拟 | ||
| 计算协方差和相关系数 | 零售行业销售数据分析 | ||
| Index类型及其子类型概述 | 抖音V数据分析可视化 | ||
| 时间序列和DatetimeIndex对象的常用方法 | 视频网站运营数据分析和可视化 | ||
| 电商大促活动数据复盘分析 | |||
| 第八周 数据分析思维和商业智能工具 | 第3天 matplotlib统计图表绘制 | Matplotlib概述 | |
| matplotlib的配置参数 | |||
| 创建画布 | |||
| 定制坐标系 | |||
| 折线图和面积图 | |||
| 散点图和气泡图 | |||
| 柱状图和堆叠柱状图 | |||
| 饼图和环状饼图 | |||
| 箱线图和小提琴图 | |||
| 雷达图和玫瑰图 | |||
| 第八周 数据分析思维和商业智能工具 | 第4天 项目实战-1 | 电商产品的生命周期 | |
| 电商用户的生命周期 | |||
| 电商产品的人货场模型 | |||
| 电商产品业务痛点和机会点分析 | |||
| 电商产品核心指标和指标体系解析 | |||
| 电商产品运营活动概述 | |||
| FAST模型和KISS复盘 | |||
| 用户画像和用户标签 | |||
| 第八周 数据分析思维和商业智能工具 | 第5天 项目实战-2 | 电商订单分析 | |
| 电商运营活动分析 | |||
| 用户画像和用户标签 | |||
| 数据分析报告撰写 | |||
| 周 统计思维及其应用 | 第1天 | 概率论概述 | 概率论和统计学概述 |
| 统计思维对数据分析的重要性 | |||
| 数据和数据的分类 | |||
| 获取数据的描述性统计信息 | |||
| 探索数据的分布 | |||
| 随机事件、样本空间和随机试验 | |||
| 概率的定义 | |||
| 复合事件和条件概率 | |||
| 随机变量的概念 | |||
| 期望和方差 | |||
| 离散型随机变量及其分布 | |||
| 第九周 统计思维及其应用 | 第2天 | 中心极限定理和假设检验 | 正态分布 |
| 数据获取和抽样 | |||
| 常用统计量 | |||
| 基于正态分布的三大分布 | |||
| 抽样均值分布 | |||
| 中心极限定理 | |||
| 假设检验的基本原理 | |||
| z检验、t检验和卡方检验 | |||
| 第九周 统计思维及其应用 | 第3天 | 区间估计和方差分析 | 参数估计的方法 |
| 点估计的实施方法 | |||
| 区间估计的原理 | |||
| 应用估计解决实际问题 | |||
| 样本容量的确定 | |||
| 区间估计和假设检验的联系 | |||
| 方差分析的基本思想 | |||
| 方差分析的实施思路 | |||
| 第九周 统计思维及其应用 | 第4天 | 相关性和回归分析 | 变量关系的确定 |
| 相关关系和相关系数 | |||
| 一元线性回归和最小二乘法 | |||
| 回归模型的验证 | |||
| 哑变量回归 | |||
| 多元线性回归 | |||
| 消除多重共线性 | |||
| 岭回归和逻辑回归 | |||
| 第九周 统计思维及其应用 | 第5天 | 时间序列分析 | 时间序列的基本定义 |
| 平稳时间序列 | |||
| 自回归模型 | |||
| 移动平均模型 | |||
| 自相关移动平均模型 | |||
| ARIMA模型 | |||
| 时间序列分析案例讲解 | |||
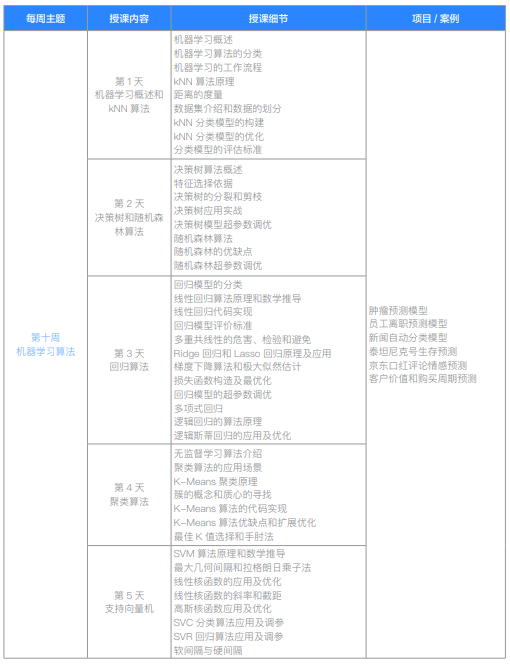
| 十周 机器学习算法 | 第1天 机器学习概述和KNN算法 | 机器学习概述 | |
| 机器学习算法的分类 | |||
| 机器学习的工作流程 | |||
| KNN算法原理 | |||
| 距离的度量 | |||
| 数据集介绍和数据的划分 | |||
| knn分类模型的构建 | |||
| knn分类模型的优化 | |||
| 分类模型的评估标准 | |||
| 第十周 机器学习算法 | 第2天 决策树和随机森林算法 | 决策树算法概述 | |
| 特征选择依据 | |||
| 决策树的分裂和剪枝 | |||
| 决策树应用实战 | |||
| 决策树模型超参数调优 | |||
| 随机森林算法 | |||
| 随机森林的优缺点 | |||
| 随机森林超参数调优 | |||
| 第十周 机器学习算法 | 第3天 回归算法 | 回归模型的分类 | 肿瘤预测模型 |
| 线性回归管理和数学推导 | 员工离职预测模型 | ||
| 线性回归代码实现 | 新闻自动分类模型 | ||
| 多重共线性的危害、检验和避免 | 泰坦尼克号生存预测 | ||
| Ridge 回归和Lasso 回归原理及应用 | 京东口碑评论情感预测 | ||
| 梯度下降算法和极大似然估计 | 客户价值和购买周期预测 | ||
| 损失函数选及最优化 | |||
| 回归模型的超参数调优 | |||
| 多项式回归 | |||
| 逻辑回归的算法原理 | |||
| 逻辑斯蒂回归的应用及优化 | |||
| 第十周 机器学习算法 | 第4天 聚类算法 | 无监督学习介绍 | |
| 聚类算法的应用场景 | |||
| K-Means 聚类原理 | |||
| 簇的概念和质心的寻找 | |||
| K-Means 算法的代码实现 | |||
| K-Means 算法优缺点和扩展优化 | |||
| 最佳K值选择和手肘法 | |||
| 第十周 机器学习算法 | 第5天 支持向量机 | SVM算法原理和数学推导 | |
| 最大几何间隔和拉格朗日乘子法 | |||
| 线性核函数的应用及优化 | |||
| 高斯核函数的斜率和截距 | |||
| 高斯核函数应用及优化 | |||
| SVC 分类算法应用及调参 | |||
| SVR 回归算法应用及调参 | |||
| 软间隔与硬问题 | |||
| 第十一周 机器学习算法 | 第1天 集成学习算法 | 集成学习概述 | 手写数字识别 |
| 集成学习算法分类 | 信用卡反欺诈模型 | ||
| 随机森林和极限树 | 旅游类 App 信息消歧客户违约预测模型 | ||
| AdaBoost 算法 | |||
| GBDT 梯度提升树 | |||
| XGBoost 算法 | |||
| LightGBM 算法 | |||
| 集成学习算法的应用领域 | |||
| 第2天 神经网络模型 | 什么是神经网络 | ||
| 神经网络与传统机器学习对比 | |||
| 神经网络的应用领域 | |||
| 感知机基本结构 | |||
| 激活函数和损失函数 | |||
| 多层神经网络原理 | |||
| 前向传播和反向传播原理 | |||
| 实现一个神经网络模型 | |||
| 深度神经网络模型和深度学习 | |||
| 深度学习在计算机视觉中的应用 | |||
| 第3天 特征工程 | 数据挖掘标准流程 | ||
| 特征工程概述 | |||
| 特征选择方法 | |||
| 主成分分析(PCA) | |||
| 线性判别分析(LDA) | |||
| t 分布随机邻域嵌入(t-SNE) | |||
| 第4天-第5天 机器学习项目实战 | 信用风险评估体系 | ||
| 申请者模型、评级模型、催收模型、欺诈模型的关系及意义 | |||
| 信用风险评级模型开发流程 | |||
| 业务场景定义(观察窗口、表现窗口) | |||
| 异常值和空值的处理 | |||
| 探索性数据分析(EDA) | |||
| WOE、IV 值意义及特征转换 | |||
| 特征重要性评估 | |||
| 模型训练和超参数调优 | |||
| 特征选择 | |||
| 特征重要性评估(RFE) | |||
| IV 值检验 | |||
| 信用评分转换和评分卡制作 | |||
| 模型监控及拒绝 | |||
| 第十二周 数据仓库和大数据挖掘 | 第1天 Linux系统概述 | Linux操作系统简介 | |
| Linux的常用发行版本介绍 | |||
| 使用SSH密钥工具介绍 | |||
| Linux系统命令讲解 | |||
| Linux系统常用工具 | |||
| Linux系统软件包的安装和管理 | |||
| Vim和Shell脚本编写 | |||
| 第2天 数据仓库基础 | 数据仓库概述 | ||
| 数据仓库分架构 | |||
| 维度建模和关系建模 | |||
| 星型模型和雪花模型 | |||
| ETL流程和相关工具 | |||
| 使用Python+pandas实现ETL流程 | |||
| 增量ETL实现方案 | |||
| 数据仓库的存储优化和安全管理 | |||
| 第3天 Hive实战 | Hadoop大数据生态圈概述 | 电商行业数仓库建设 | |
| 安装和配置Hive环境 | 用户行为数据采集和分析 | ||
| 配置和初始化Hive元数据库 | 用户购买和流失预测分析 | ||
| 启动和验证Hive | 大促活动备货和销售预测 | ||
| HiveSQL语法和数据类型 | |||
| 创建数据库和表 | |||
| 加载数据到Hive表 | |||
| Hive查询操作 | |||
| 分区表和分桶表 | |||
| 管理表和外部表 | |||
| Hive常用内置函数 | |||
| 性能调优优化 | |||
| 第4天 PySpark大数据分析 | Spark架构与核心组件 | ||
| RDD、DataFrame、Dataset | |||
| Spark本地环境和集群环境 | |||
| 安装与配置PySpark | |||
| 数据读取和基本操作 | |||
| 数据清洗和转换 | |||
| 使用Spark SQL执行复杂任务 | |||
| PySpark MLlib的应用 | |||
| PySpark Streaming和实时数据处理 | |||
| 第5天 数据仓库项目实战 | 项目需求与目标 | ||
| 数据源介绍 | |||
| 企业级数据仓库设计 | |||
| 数据加载和准备 | |||
| 使用Hive进行数据查询与分析 | |||
| Spark SQL与Hive整合 | |||
| 查询性能优化 | |||
| BI工具接入和数据可视化 | |||
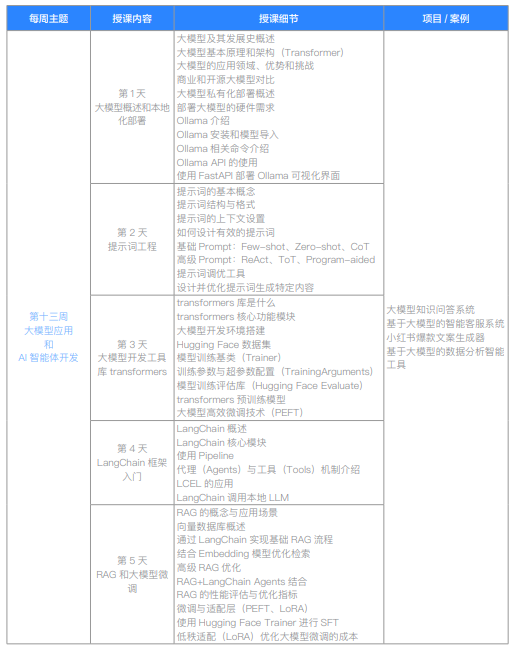
| 第十三周 大模型应用和AI智能体开发 | 第1天 大模型概述和本地化部署 | 大模型及其发展史概述 | |
| 大模型基本原理和架构(Transformer) | |||
| 大模型的应用领域、优势和挑战 | |||
| 商业和开源大模型对比 | |||
| 大模型私有化部署概述 | |||
| 部署大模型的硬件需求 | |||
| Ollama 介绍 | |||
| Ollama 安装和模型导入 | |||
| Ollama 相关命令介绍 | |||
| Ollama API 的使用 | |||
| 使用 FastAPI 部署 Ollama 可视化界面 | |||
| 第2天 提示词工程 | 提示词的基本概念 | ||
| 提示词结构与格式 | |||
| 提示词的上下文设置 | |||
| 如何设计有效的提示词 | |||
| 基础 Prompt: Few-shot, Zero-shot, CoT | |||
| 高级 Prompt: ReAct, ToT, Program-aided | |||
| 提示词调优工具 | |||
| 设计并优化提示词生成指定内容 | |||
| 第3天 大模型开发工具库 transformers | transformers 库是什么 | 大模型知识问答系统 | |
| transformers 核心功能模块 | 基于大模型的智能客服系统 | ||
| 大模型开发环境搭建 | 小红书爆款文案生成器 | ||
| Hugging Face 概述 | 基于大模型的数据分析智能工具 | ||
| 模型训练基类(Trainer) | |||
| 训练参数与超参数配置(TrainingArguments) | |||
| 模型训练评估方法(Hugging Face Evaluate) | |||
| transformers 预训练模型 | |||
| 大模型高效微调技术(PEFT) | |||
| 第4天 LangChain 框架入门 | LangChain 概述 | ||
| LangChain 核心模块 | |||
| 使用 Pipeline | |||
| LCEL 的应用 | |||
| LangChain 调用本地 LLM | |||
| RAG 的概念与应用场景 | |||
| 向量数据库概述 | |||
| 第5天 RAG 和大模型微调 | 通过 LangChain 实现基础 RAG 流程 | ||
| 结合 Embedding 模型优化检索 | |||
| 高级 RAG 优化 | |||
| RAG+LangChain Agents 结合 | |||
| RAG 的性能评估与优化指标 | |||
| 微调与适配层(PEFT, LoRA) | |||
| 使用 Hugging Face Trainer 进行 SFT | |||
| 低秩适配(LoRA)优化大模型微调的成本 | |||
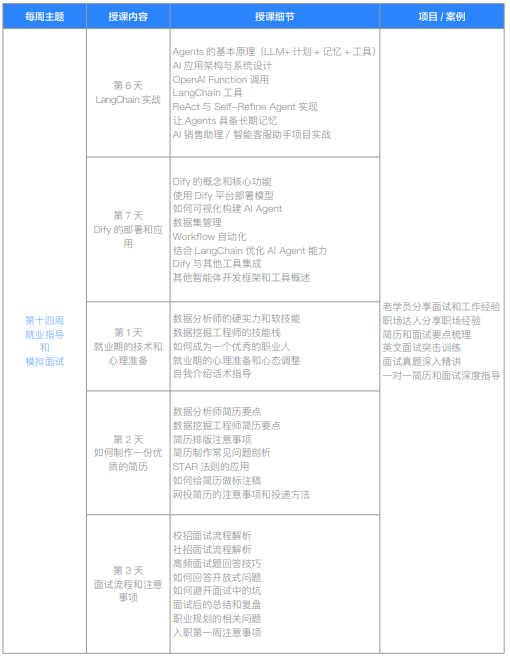
| 第十四周 职业指导和模拟面试 | 第1天 LangChain 实战 | Agents 的基本原理(LLM+计划+记忆+工具) | |
| AI应用架构与系统设计 | |||
| OpenAI Function 调用 | |||
| LangChain 工具 | |||
| ReAct 与 Self-Refine Agent 实现 | |||
| 让 Agents 具备长期记忆 | |||
| AI 销售助理 / 智能客服助手项目实战 | |||
| 第2天 Dify 的部署和应用 | Dify 的概念和核心功能 | ||
| 使用 Dify 平台部署模型 | |||
| 如何可视化构建 AI Agent | |||
| 数据集管理 | |||
| Workflow 自动化 | |||
| 结合 LangChain 优化 AI Agent 能力 | |||
| Dify 与其他工具集成 | |||
| 其他智能体开发框架和工具概述 | |||
| 第3天 就业期的技术和心理准备 | 数据分析师的硬实力和软技能 | 老学员分享面试和工作经验 | |
| 数据挖掘工程师的能力栈 | 职场达人分享职场经验 | ||
| 如何成为一个优秀的职业人 | 简历和面试要点梳理 | ||
| 就业期的心理准备和心理调整 | 英文面试突击训练 | ||
| 自我介绍话术指导 | 面试真题深入精讲 | ||
| 一对一简历和面试深度指导 | |||
| 第4天 如何制作一份优质的简历 | 数据分析师简历要点 | ||
| 数据挖掘工程师简历要点 | |||
| 简历排版注意事项 | |||
| 简历制作常见问题剖析 | |||
| STAR 法则的应用 | |||
| 如何给简历做标注稿 | |||
| 网投简历的注意事项和投递方法 | |||
| 第5天 面试流程和注意事项 | 校招面试流理解析 | ||
| 社招面试流理解析 | |||
| 高频面试题回答技巧 | |||
| 如何回答开放式问题 | |||
| 如何避开面试中的坑 | |||
| 面试后的总结和复盘 | |||
| 职业规划的相关问题 | |||
| 入职第一周注意事项 |
项目一:全科医院就诊和收支数字化大屏
项目背景
核心指标的数据监控和数字驾驶舱是企事业单位在数字化转型上的一个里程碑,项目以某全科医院就诊和收支数据为基础,展示了如何使用商业智能工具实现收入、支出、利润、就诊满意度等核心指标的监控以及数据的同比、环比,通过对数据按就诊时间、地域、病症、科室、就诊类别等维度进行拆解和逐级钻取,掌握数据的构成及其随时间的变化,各类数据以柱状图、瀑布图、树状图、饼图、地图等方式呈现,最终构成数字驾驶舱并产生相应的业务洞察。
相关知识
Power Bl Desktop、Power Query、数据清洗数据建模、事实表、维度表、星型模型、度量值、DAX、视觉对象、筛选器、细分分析法、同比、环比报表、Power Bl Pro
应用场景
企业数据可视化、核心指标监控、数字化大屏数字驾驶舱、业务洞察
项目二:连锁咖啡店用户和产品画像分析
项目背景
新品牌重视直连用户(Direct To Customer),以消费者的需求为牵引力,将产业链条上各个环节整合在自己手中,数据前后打通,然后基于用户数据不断优化产品,构建用户忠诚度金字塔,实现对各级用户的深耕。本项目以某连锁咖啡店销售数据为基础,展示如何对用户数据和产品数据进行多维度细分,构建自身产品画像并以此为基础实现产品的优化;掌握用户的产品偏好、消费能力、支付习惯,最终实现用户进行价值分群以及对不同用户群体的精细化运营。
相关知识
Tableau Desktop、Tableau Prep、雪花模型、计算字段、数据桶、参数、快速表计算、LOD表达式、平均线、趋势线、象限法、细分分析法、相关分析法、RFM 模型、仪表板、故事、Tableau Server、Tableau Public
应用场景
核心指标监控、数字驾驶舱、用户价值分群、产品画像
项目三:零售行业利润下滑诊断分析
项目背景
利润水平是企业的生命线,利润或利润率不仅仅是财务报表中的一个数据,更应该是企业日常数据监控中的一项重要指标,财务人员通常比较关心净利润,数据分析师则更关注毛利润和毛利润率。本项目以某连锁超市门店、商品和销售数据为基础,展示如何运用可视化图表监控销售和利润数据,在遇到毛利润异常下滑时,如何通过公式拆解法和细分分析法快速锁定异常原因,并输出相应的分析报告有非常高的实用价值。
相关知识
对比法、拆解法、象限分析法、地图组件、维度下钻,DAX、智能叙述、分解树
应用场景
核心指标监控、数字化大屏、数字驾驶舱、数据异常诊断和分析
项目四:金融行业信用风险评分卡模型
项目背景
信用凤险指的是交易对手未能履行约定合同中的义务造成经济损失的风险,即受信人不能履行还本付息的责任而使授信人的预期收益与实际收益发生偏离的可能性,它是金融风险的主要类型。借贷场景中的评分卡是一种以分数的形式来衡量风险几率的-种手段,也是对未来一段时间内违约、逾期、失联概率的预测。本项目使用逻辑回归算法通过对历史逾期样本数据的学习建立评分卡模型,将特征数据映射成分箱的分值,最终给出申请人的信用分数。一般来说,分数越高,风险越小。
相关知识
NumPy、pandas、seabom、EDA(探索性数据分析)、scikit-leam、特征工程、逻辑回归、AUC、ROC、KS、PSI
应用场景
消费金融、信用卡申请审批、贷款自动审核





